LightGBM提出动机
为了解决GBDT在海量数据中遇到的问题,让GBDT算法更好的适用于工业实践。
1、XGBoost的缺点
- 需要保存特征值和排序结果,还需要保存排序的索引
- 每次分裂一个点的时候,都需要计算收益
- 对cache优化不友好,容易造成cache miss
2、LightGBM的优化
- 单边梯度采样GOSS
- 直方图算法
- 互斥特征捆绑算法
- Leaf-Wise分裂算法
- 类别特征最有分裂
- 并行学习优化
- cache命中率优化
2. 数据原理
2.1.基于直方图的算法
对于XGBoost,其实现是预排序算法,LiggtGBM是基于直方图的算法。

直方图算法计算过程
- 遍历每一个叶子结点的每一个特征
- 为每一个特征创建一个直方图,将样本的梯度($g_i$)之和和样本数$n$保存到bin中
- 然后遍历所有的bin,以当前的bin作为分裂点,然后计算分裂后的左右节点梯度和节点数目
- 通过直方图加速法算出左右节点的梯度和$S_L$和$S_R$,已经bin的数量
- 计算分裂后的收益$loss=\frac{S_L^2}{n_L}+\frac{S_R^2}{n_R}-\frac{S_P^2}{n_p}$
其实,思想和xgb差不多,在选择分裂点的时候,xgb用的是预排序算法,lgb用的是梯度直方图。
然后在计算上的代价也大幅降低,预排序算法每遍历一个特征值就需要计算一次分裂的增益,而直方图算法只需要计算k次(k可以认为是常数),时间复杂度从O(#data#feature)优化到O(k#features)。
直方图离散化优点:
- 占用内存更小,相对于XGBoost预排序算法,无需存储特征值和排序索引
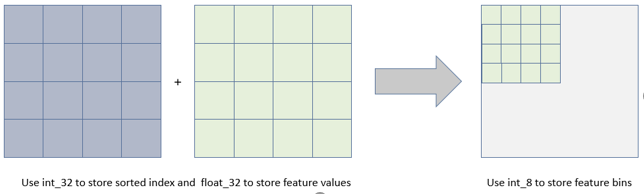
- 计算代价更小,预排序算法需要每遍历一个特征值,就计算一次收益,而直方图算法只用计算K次,时间复杂度有O(data feature)下降到O(k feature)
当然,Histogram算法并不是完美的。由于特征被离散化后,找到的并不是很精确的分割点,所以会对结果产生影响。但在不同的数据集上的结果表明,离散化的分割点对最终的精度影响并不是很大,甚至有时候会更好一点。原因是决策树本来就是弱模型,分割点是不是精确并不是太重要;较粗的分割点也有正则化的效果,可以有效地防止过拟合;即使单棵树的训练误差比精确分割的算法稍大,但在梯度提升(Gradient Boosting)的框架下没有太大的影响。
2.2 单边梯度采样GOSS
对于GBDT的数据,梯度越大,说明训练误差越大,这样的样本对模型的提升也越大(adaboost思想),因此GOSS的算法的思想是保留梯度交大的样本,然后在剩余梯度较小的样本中进行采样。不直接丢掉梯度较小的样本数据的原因是会影响数据总体分布。
具体流程
- 首先将分裂的特征按照绝对值大小进行排序
- 选择梯度最大的a%的数据
- 在剩余的数据中随机挑选b%个数据
- 然后对于梯度较小的数据,乘以1个常数$\frac{1-a}{b}$
- 最后将挑选出来的数据进行合并,计算信息增益

2.3 互斥特征捆绑算法
互斥捆绑算法的目的是为了减少特征维度,因为实际任务中,特征一般是高维稀疏的。
对于完全互斥的特征,可以将其捆绑起来,例如one-shot产生的特征,捆绑之后不会造成信息丢失。
对于不完全互斥的特征,存在部分情况下两个特征都为非0值,可以使用冲突比率(同时不为0的样本数之和/所有样本数)对不互斥程度进行衡量,当小于一定值时,可以将两个不完全互斥的特征捆绑。
对于特征捆绑,有两个问题
1、如何确定哪些特征需要绑在一起
2、如何构建绑定后的特征
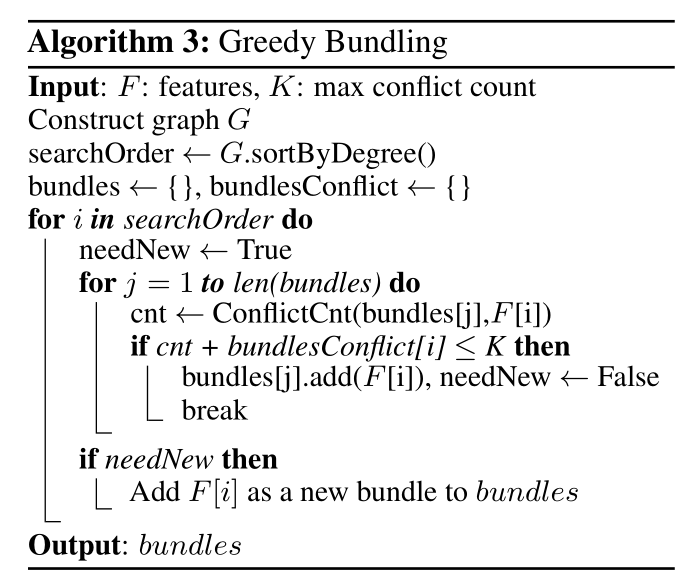
对于第一个问题,确定那些问题需要绑定,LightGBM的做法如下
1、构建一个无向加权图,顶点表示特征,边的权值大小表示冲突比率
2、基于特征在图中的度数进行降序排序
3、遍历每个捆绑特征,检查捆绑之后特征数是否小于最大冲突数
- 冲突数小于K,将该特征添加到捆绑
- 冲突数大于K,创建新的捆绑特征
对于第二个问题,如何构建绑定后的特征,关键在于如何从绑定后的特征识别出原始特征中的值。基于直方图算法存储的是离散的箱子,而不是连续的特征值。LightGBM是基于特征从属于不同的箱子来构建捆绑特征的。假设特征A的原始特征取值空间为[0,10),特征B的取值空间为[0,20),当 此时可以在特征B的区间上加上偏置10,此时B的取值空间为[10,20),而AB绑定后的特征取值空间为[0,30)。

EFB算法可以将很多互斥稀疏特征捆绑成少量稠密特征,避免针对特征值0的不必要计算。虽然可以优化基于直方图的算法,使用一张表保存每个特征非0取值,然后通过扫描这张表来构建直方图,这样时间复杂度就从原来的O(data)变成了O(no_zero_data),缺点在于需要额外的算力和空间保存和更新这张表。LGB将其作为辅助功能。
2.4 Leaf-Wise分裂算法
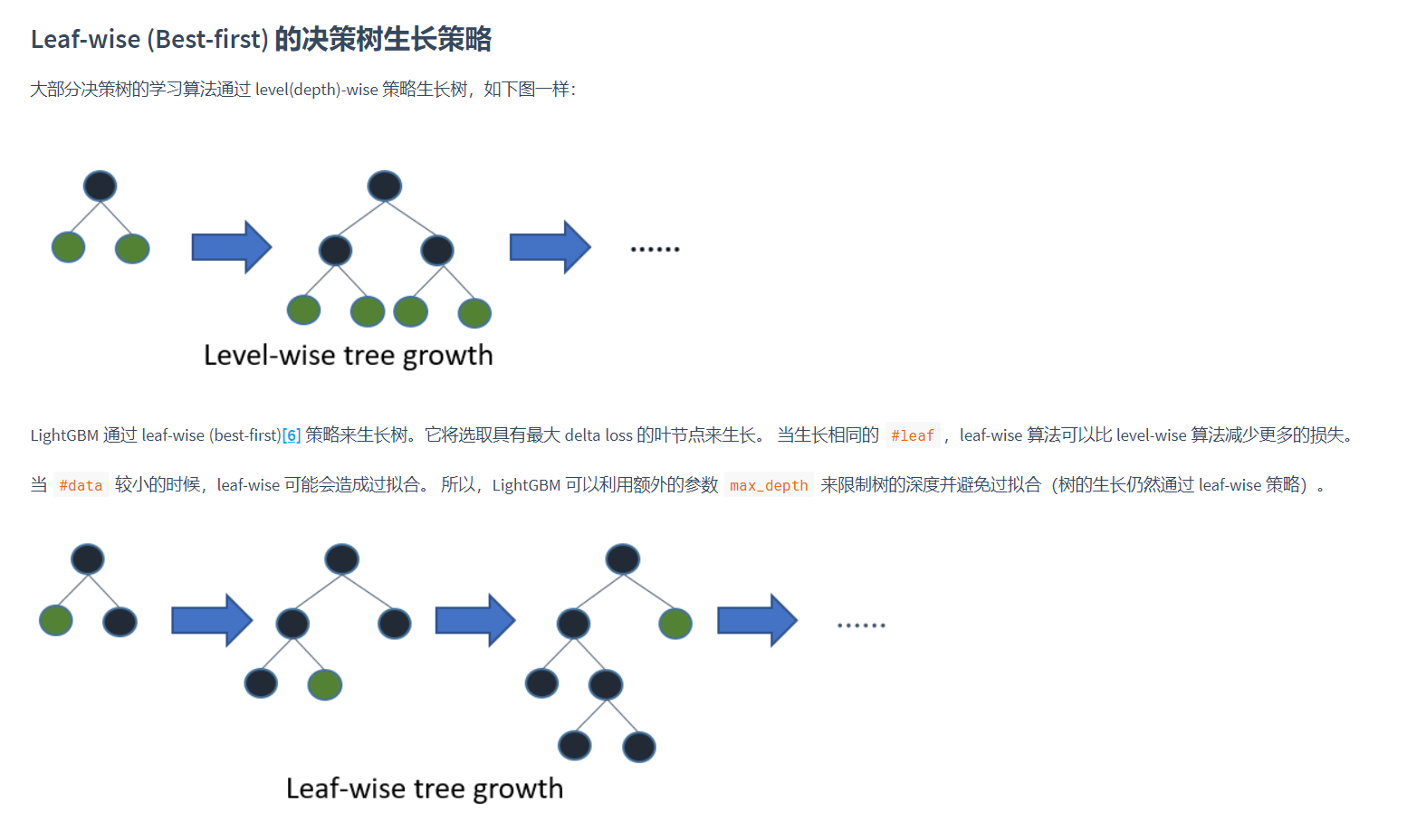
2.5 类别特征最优分裂
这部分没怎么看懂,参考的
- 离散特征建立直方图的过程:统计该特征下每一种离散值出现的次数,并从高到低排序,并过滤掉出现次数较少的特征值, 然后为每一个特征值,建立一个bin容器, 对于在bin容器内出现次数较少的特征值直接过滤掉,不建立bin容器。
- 计算分裂阈值的过程:
- 先看该特征下划分出的bin容器的个数,如果bin容器的数量小于4,直接使用one vs other方式, 逐个扫描每一个bin容器,找出最佳分裂点;
- 对于bin容器较多的情况, 先进行过滤,只让子集合较大的bin容器参加划分阈值计算, 对每一个符合条件的bin容器进行公式计算(公式如下: 该bin容器下所有样本的一阶梯度之和/该bin容器下所有样本的二阶梯度之和 + 正则项(参数cat_smooth),这里为什么不是label的均值呢?其实上例中只是为了便于理解,只针对了学习一棵树且是回归问题的情况, 这时候一阶导数是Y, 二阶导数是1),
3 工程优化
3.1 并行学习优化
LightGBM 提供以下并行学习优化算法:
特征并行
适用于数据量比较少,feature比较多
传统的特征并行算法旨在于在并行化决策树中的“ Find Best Split.主要流程如下:
- 垂直划分数据(不同的机器有不同的特征集)
- 在本地特征集寻找最佳划分点 {特征, 阈值}
- 本地进行各个划分的通信整合并得到最佳划分
- 以最佳划分方法对数据进行划分,并将数据划分结果传递给其他线程
- 其他线程对接受到的数据进一步划分
然而,该特征并行算法在数据量很大时仍然存在计算上的局限。因此,建议在数据量很大时使用数据并行。
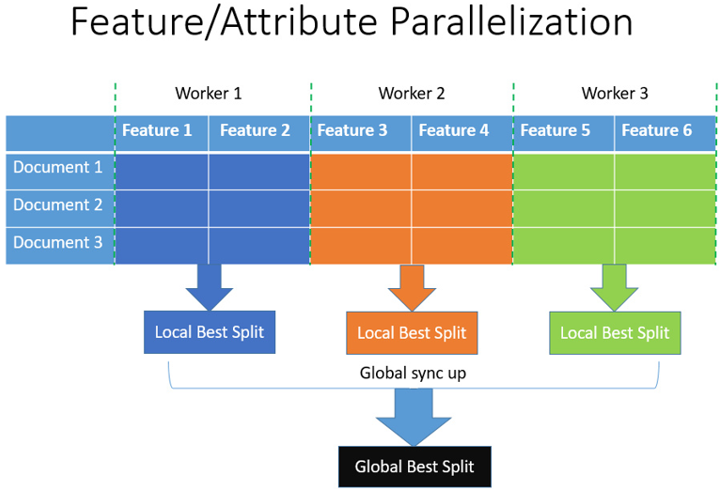
数据并行
适用于大数据,feature比较少
数据并行旨在于并行化整个决策学习过程。数据并行的主要流程如下:
- 水平划分数据
- 线程以本地数据构建本地直方图
- 将本地直方图整合成全局整合图
- 在全局直方图中寻找最佳划分,然后执行此划分
数据并行的缺点
- 机器的通讯开销大约为 “O(#machine #feature #bin)” 。 如果使用集成的通讯算法(例如, “All Reduce”等),通讯开销大约为 “O(2 #feature #bin)”[8] 。
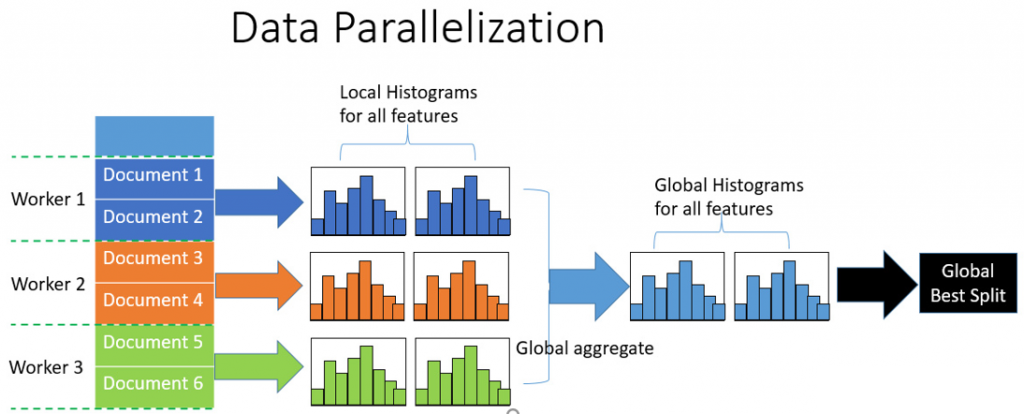
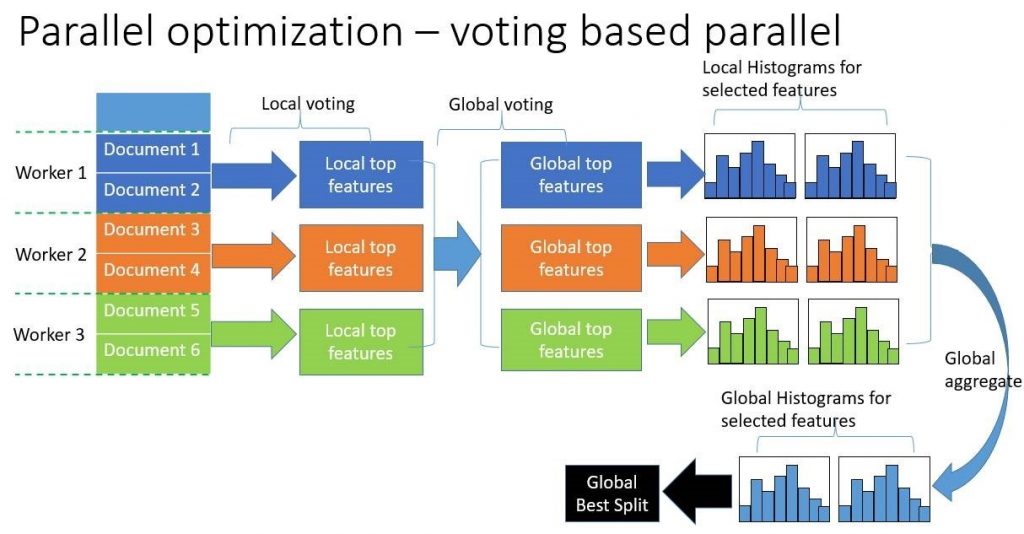
投票并行
大数据并且feature比较多
基于投票的并行是对于数据并行的优化,主要分为两步:
- 通过本地数据,找到本地top k的特征
- 利用投票筛选出可能是全局最优点的特征
- 合并直方图时,只合并被选出来的部分
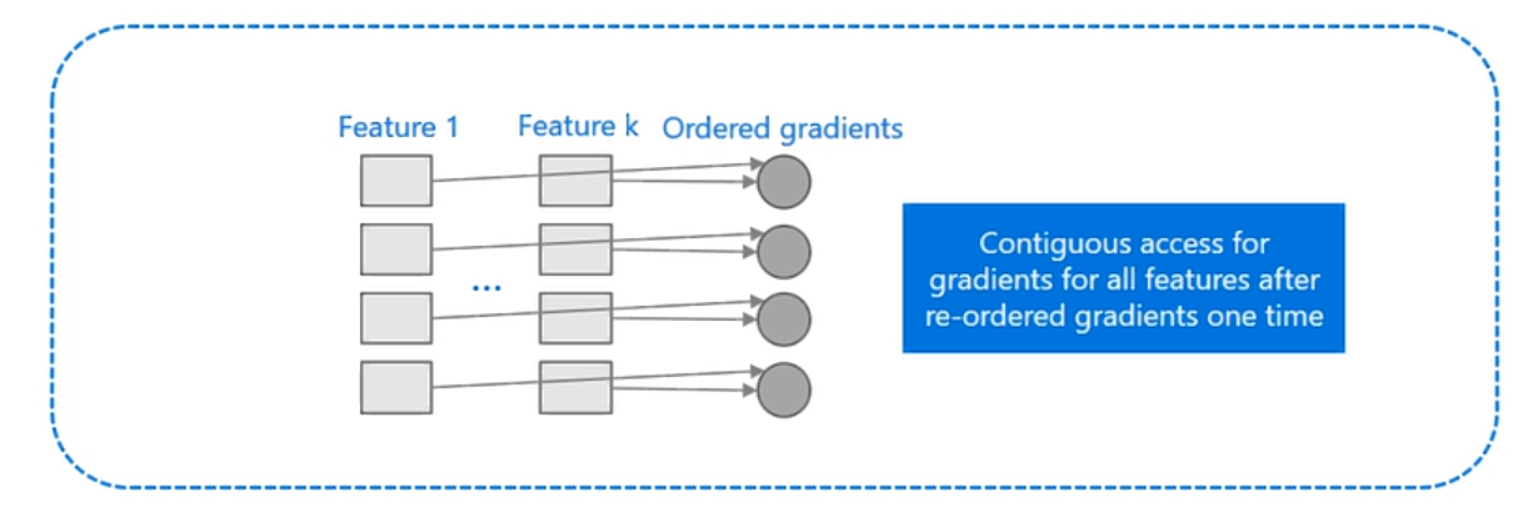
3.2 Cache命中率优化
预排序算法:
- 不同的特征访的梯度顺序不同
- 对于索引表的访问,pre_sort使用了行号和叶子节点的索引表
- 都是随机访问,容易造成cache miss
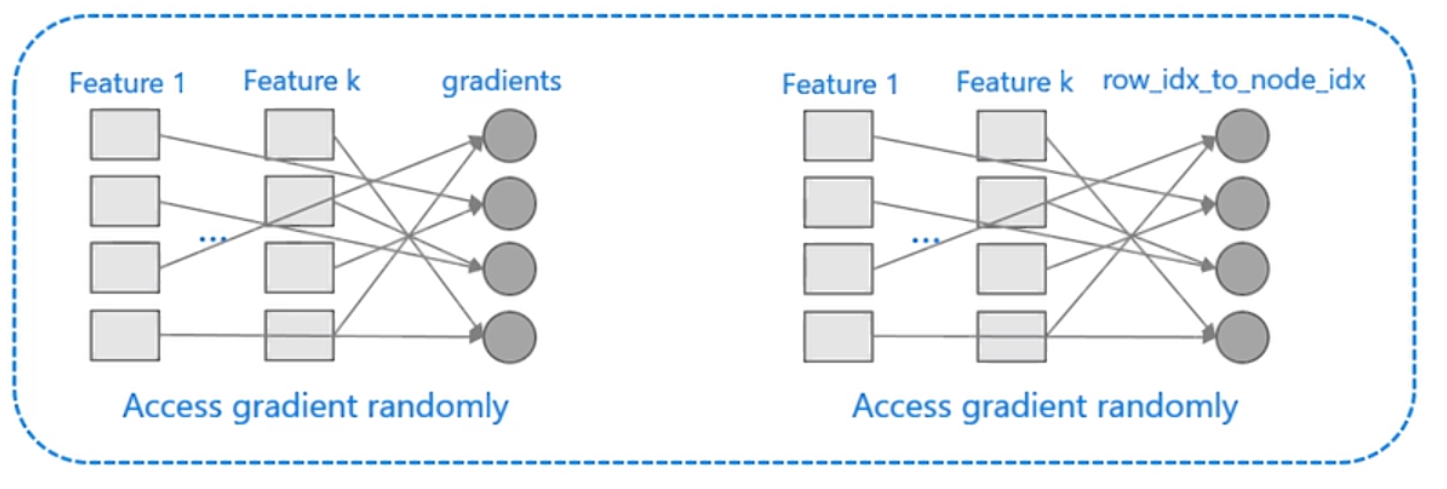
lightGBM对直方图优化:
- 梯度直方图不需要对梯度进行排序
- 直方图算法不需要数据到叶子id的索引表
4 XGBoost和LightGBM区别
- xgboost是预排序算法,lightGBM是直方图算法。
- 分裂方式,xgb是level-wise,lgb是Leaf-Wise
- lgb支持类别特征
- 采用了单边梯度采样和互信息捆绑进行优化
- 并行化,feature在节点进行分裂的时候采用了多线程并行化,而lgb采用了特征并行、数据并行、投票并行
- 基于分裂算法的不同,lgb对cache命中更加高效
参考
1、https://cloud.tencent.com/developer/article/1528372
2、https://mp.weixin.qq.com/s/M25d_43gHkk3FyG_Jhlvog
3、https://www.biaodianfu.com/lightgbm.html
4、https://www.zhihu.com/question/266195966
