一问搞懂词向量
词向量
将数据从高维空间向低维空间映射,虽然降维了,但是包含语意信息
word2vec
两种网络结构:
- CBOW:输入$w_t$周边,得到$w_t$
- Skip-gram:输入$w_t$,得到其周边
优化方式
- 负采样
- 层次softmax
FastText
TextCNN
transfromer论文笔记
transformer提出的目的:
- 解决rnn/lstm等序列过长时出现的长期依赖问题
- 解决序列模型并行化的问题,rnn类模型当前$t$时刻的计算需要依赖$t-1$时刻的计算结果
Transformer做出的贡献:
- 抛除了CNN/RNN,完全采用注意力机制,增加了并行度
- 采用position encode,将序列距离缩放到常量
- 在nlp任务重能达到当前最先进的
网络结构
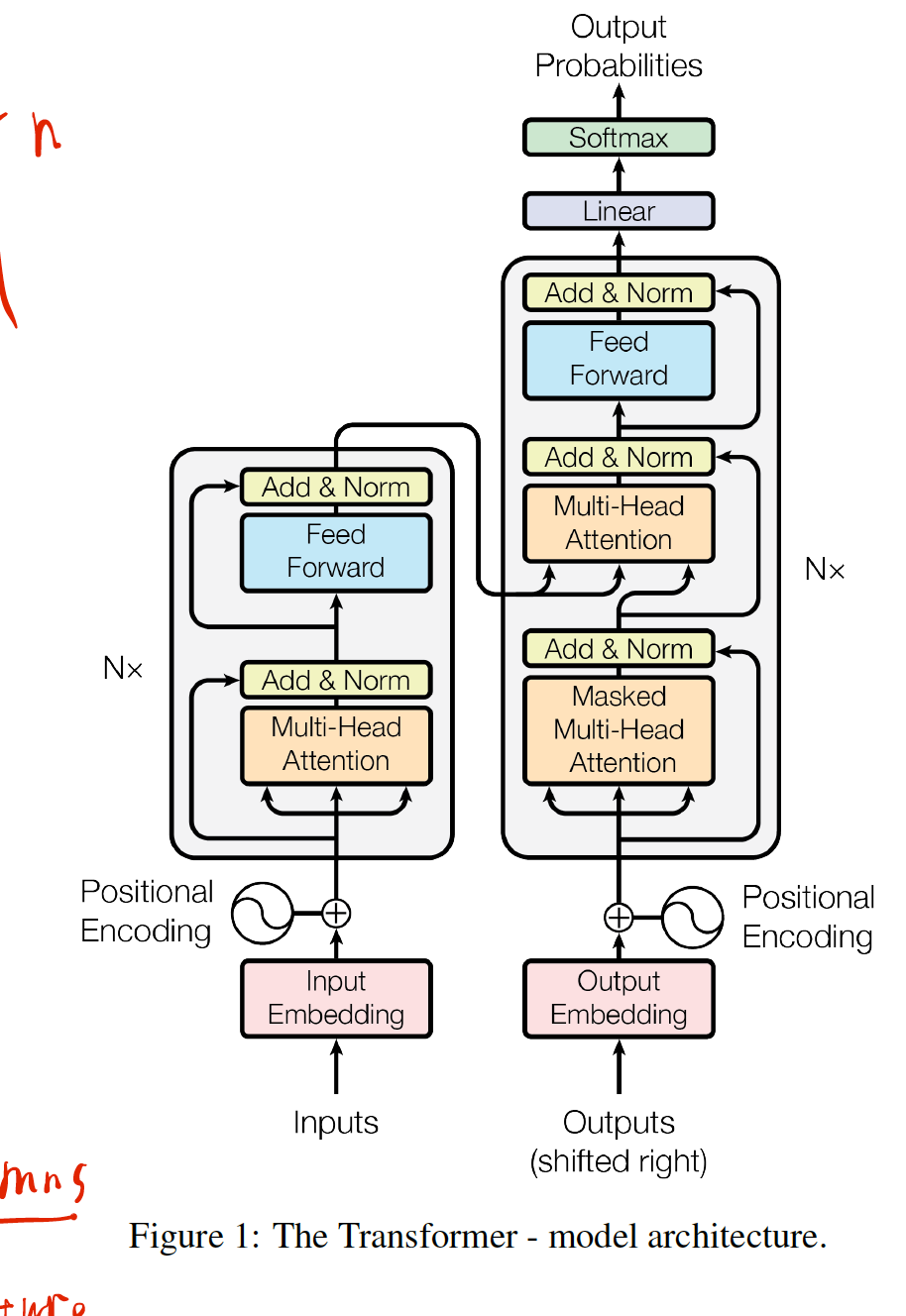
transformer整体采用的是一个encoder-decoder架构
关于KQV讲得不错的一篇博客
https://zhuanlan.zhihu.com/p/410776234
Encoder和Decoder层
Encoder
Encoder包含6层网络,每一层网络有两层子网络。第一层是多头注意力机制,第二个子层是简单神经网络。
对于一层网络的两个子层之间,采用残差网络来连接。每一个子层之间都是用layer normalization,所以每个子层的输出为
并且为了实现残差连接,每个子层的embedding输出的维度$d_{model}$都相等,为512维
Decoder
和encoder一样,由6层网络组成,每层网络比encoder多了一层mask multi-head attention layer的子层,防止编码位置泄露,使得预测的每一个位置都依赖的是前面已知的输出,其实就是防止数据泄露。
Attention
注意力机制,其实就是query和value向量映射到一个输出向量,输出向量作为value的加权和。
Scaled Dot-Product Attention
其实就是一个普通的attention归一化了。
Attention的输出为
国外一篇博客的翻译
https://zhuanlan.zhihu.com/p/48508221
解释了使用Dot Attention和归一化的原因
- 使用Dot-product attention而不是Addive attention的原因是在实际实现当中,Dot Attention更快并且空间效率更高。
- 当$d_k$的值比较小的时候,两种注意力机制结果差不多。$d_k$的值比较大的时候,加法表现得更好。因此论文假设当$d_k$维度比较大的时候,点乘的结果会变得很大,导致softmax的函数出现梯度消失的问题。为了克服这个影响,进行了归一化。
Multi-Head Attention
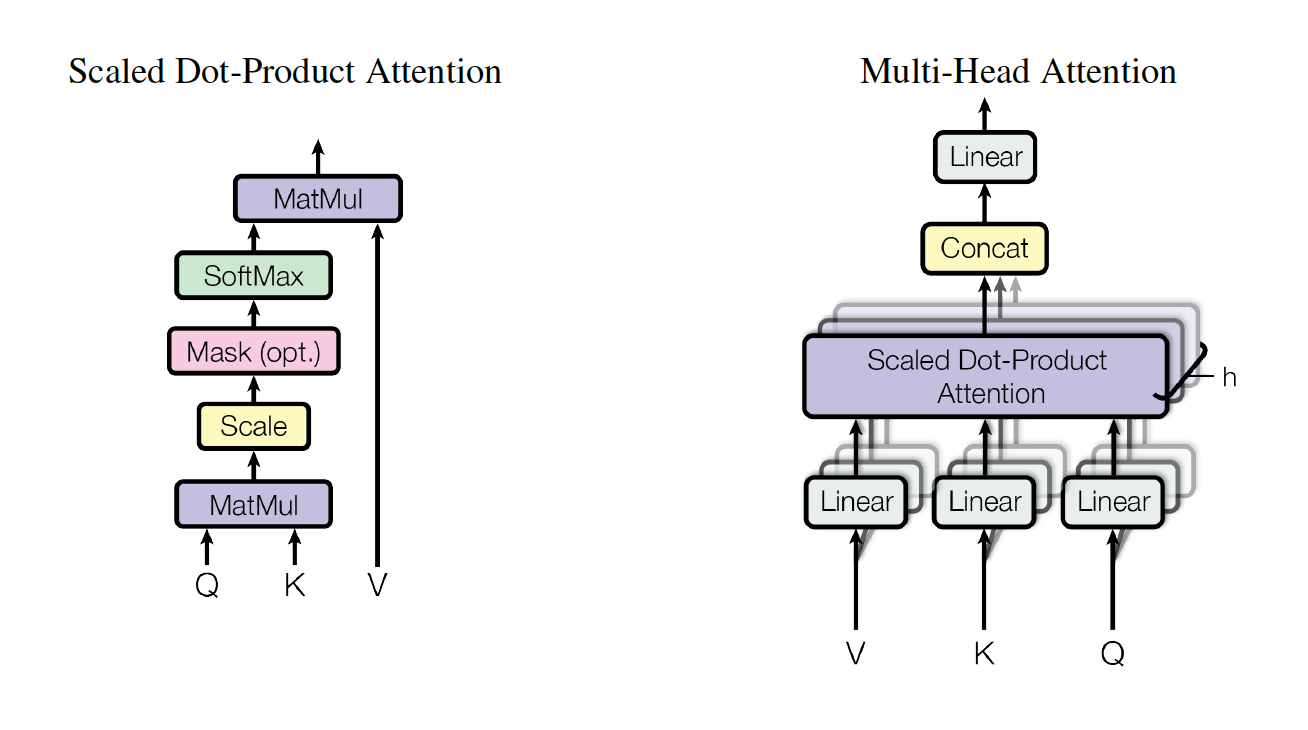
multi-head其实也很好理解,其实就是将一个self-attention映射了多次,然后将其结果拼接起来。这么做的好处是可以将不同位置的不同表达子空间关联起来。
论文中说明了h=8,$d_k=d_v=d_{model}/h=64$.
论文总结了在transformer中使用注意力机制的三个不同的方式
Position-wise Feed-Forward Networks
FNN的计算公式为
Embeddings and Softmax
暂时没看出来写了个啥
Positional Encoding
由于没有RNN或者卷积,所以为了使用序列的顺序,transformer在输入的embedding底部都加了position encoding,positional encoding和embedding有相同的维度$d_{model}$,方便两者相加。
Positional encoding有两种计算方式, sin和cos
pos表示当前词的位置,i表示的是纬度,所以假设某个词的位置编码为pos=1,那么对应的编码为
采用positional encoding的原因
- 需要体现一个单词在不同位置的区别
- 体现先后次序,一定范围内编码差异不依赖长度
- 能够将编码的值缩放到一定的范围
https://www.zhihu.com/question/347678607
https://zhuanlan.zhihu.com/p/44121378
https://zhuanlan.zhihu.com/p/48508221
bert
主要贡献:
- 提出了双向预训练模型的表示,使用MLM 语言模型能够预训练双向深度表示。因为对于语言模型来说,一个词的意思不仅和左边有关系,可能和右边的句子也存在着关系。
- 证明了预训练表示能够降低对于特定任务专门设计架构的需求
- 在11项nlp任务达到当前领先的水平
框架架构:
bert主要有两个步骤,一是pre-training,二是fine-tune
pre-training一般是在未标注数据上训练的,fine-tune则是在不同的模型上进行训练微调,bert最显著的特点就是统一了不同任务的结构,意思是bert具有通用性。
bert模型结构
bert是一个多层双向transformer组成的,在论文中提到了$Bert_{base}$和$Bert_{larg}$两个模型,其实就是参数不一致。
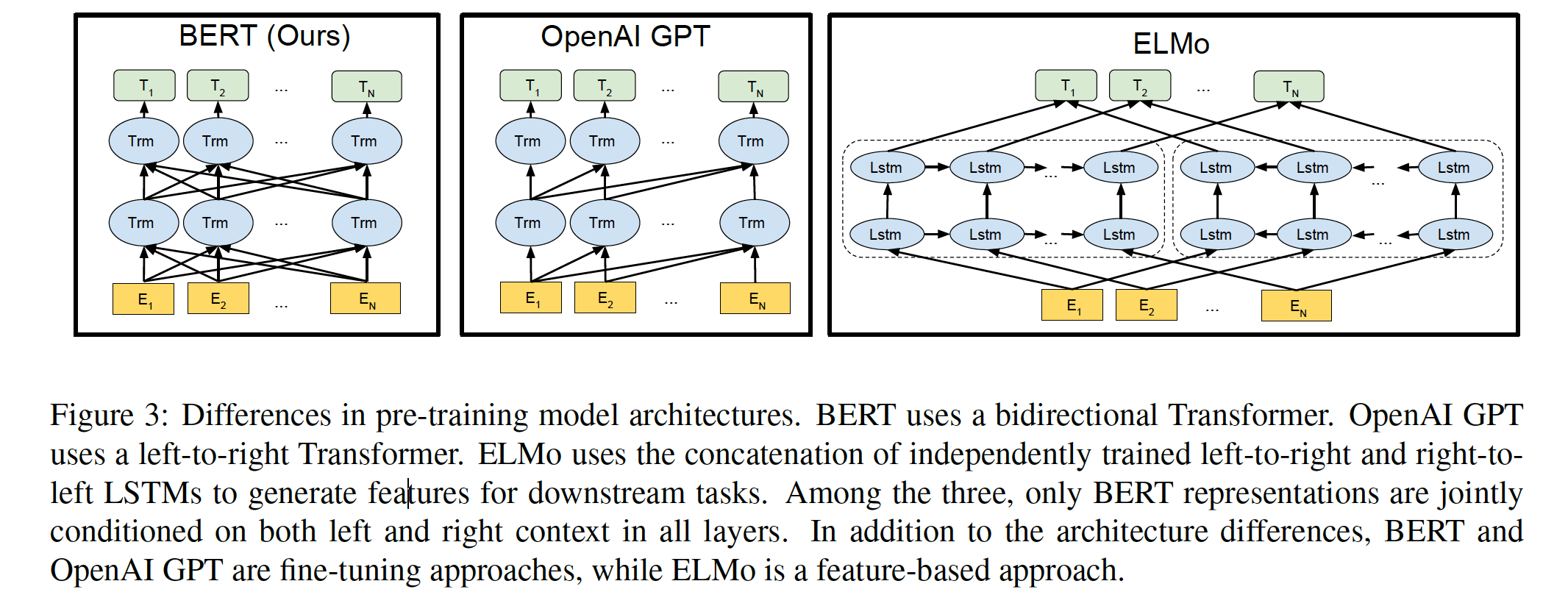
对比来说GPT采用的是单向transformer,ELmo采用是双向lstm,但是目标函数其实是不一样的,ELMo的目标函数分别为$P(w_i|w_1,w_2,…,w_{i-1})$和$P(w_i|w_{i+1},w_{i+2},…,w_{i+n})$。
Bert输入表示
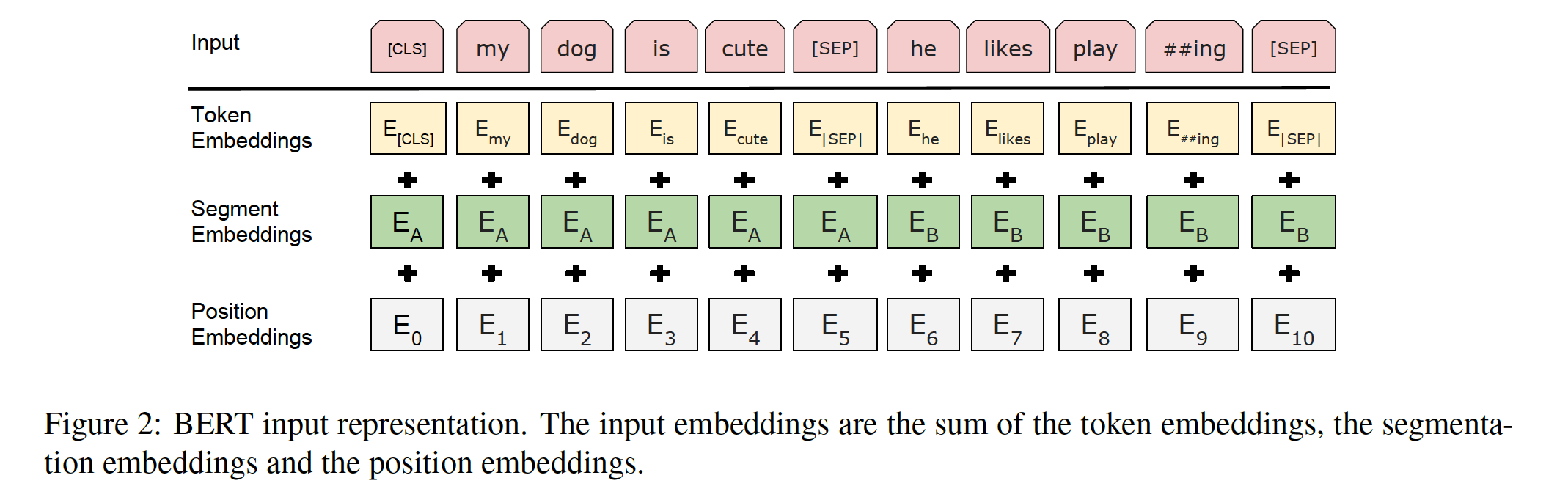
Bert输入表示分为三个embedding
- Token Embeddings:词向量embedding,对于每一句的开头,都有cls标识,最后隐藏层对应这个token的作为分类任务的表示
- Segment Embeddings:判断当前的token到底是属于sentence A还是sentence B
- Position Embeddings:每个词向量的位置embedding,不同于transformer,Bert的位置embedding是学出来的
需要注意的一点,bert在处理句子对的时候,是将其打包起来,和单个句子一样处理,但是有sep作为分隔符。
pre-training
MLM
masked language model,随机将句子中的某些词进行遮掩,然后预测被遮掩的词。在所有的Token当中随机选择15%的词用[mask]遮掩掉。但是不能一直使用[masked]作为遮掩,因为在fine-tune阶段,并不会碰到[mask],所以为了减少影响,采用三种不同的策略。
- 80%的token使用[mask]来遮掩
- 10%的token使用真实token代替
- 10%的token不进行遮掩操作。
这样做的目的是使模型不知道哪个token被mask了,所以会关注每一个词。
NSP
Next Sentence Prediction,对于不同的下游任务,例如问答系统或者自然语言推理是基于两个句子的关系,这没有被语言模型直接捕捉到,所以在建模的时候,输入句子A和句子B,B有一半的机率是A的下一句,50%的机率从句子中随机选择的,然后通过模型来预测A和B是否为下一句,模型准确率能达到97%。
Fine-Tune
由于Transformer的attention机制,可以直接使用bert来处理下游的任务。对于包含文本对的输入/输出,其他方法是先分开编码然后再拼接。而bert直接拼接在一起使用双向self-attention,化繁为简。
对于分类任务,直接去[cls]最后输出层的final hidden state然后接入softmax做预测。文章也讲了下可调参数,其实也没啥,就batch size,learning_rate之类的。
参考资料:
https://zhuanlan.zhihu.com/p/46652512
https://zhuanlan.zhihu.com/p/49271699
Graph embedding
deepwalk
node2vec
line
eges
https://zhuanlan.zhihu.com/p/49271699
nlp几大基本任务
