召回之协同过滤算法 发表于 2020-10-25 更新于 2020-11-08 分类于 推荐系统 UserCFItemCF矩阵分解MF矩阵分解其实和《推荐系统实战》那本书里面说的隐语意模型差不多多的意思,都是将用户-物品矩阵分解为用户矩阵和物品矩阵。分解的方法采用梯度下降。NCF损失函数: pointwise,用于回归模型,最小化$\hat y_{ui}$和他的目标值$y_{ui}$之间的平方损失函数。 pairwise,思想史观测实例应该被排到为观测实例前面。观测到的entry $\hat y_{ui}$和为观测到的entry $y_{ui}$之间的差 阅读全文 »
《深度学习推荐系统》阅读笔记(二) 发表于 2020-08-26 更新于 2020-12-07 分类于 机器学习 , 推荐系统 Embedding作用及应用Embedding也是编码方式的一种,主要作用是将稀疏向量转换成稠密向量。Embedding是深度学习的基础核心操作,主要有一下三个原因1、推荐场景下会使用one-hot对类别和id进行编码,造成大量稀疏数据,神经网络无法很好地处理这种稀疏数据2、Embedding本身是极强的特征向量,可以引入任何信息进行编码。 阅读全文 »
《深度学习推荐系统》阅读笔记(一) 发表于 2020-08-24 更新于 2020-10-22 分类于 机器学习 , 推荐系统 传统模型协同过滤1、User-CF的缺点 一般用户数量远大于物品数,用户相似度矩阵较大,不便于存储。同时用户数增长会造成在线存储系统难以承载扩张速度 用户历史数据向量往往比较稀疏,User-CF不适用于正反馈获取比较困难的场景,例如大件商品购买等低频应用 2、User-CF和Item-CF的使用场景 User-CF适用于新闻推荐场景,具有较强的社交性、更容易发现热点 Item-CF适用于兴趣变化比较稳定的应用,比如电商和视频推荐场景 阅读全文 »
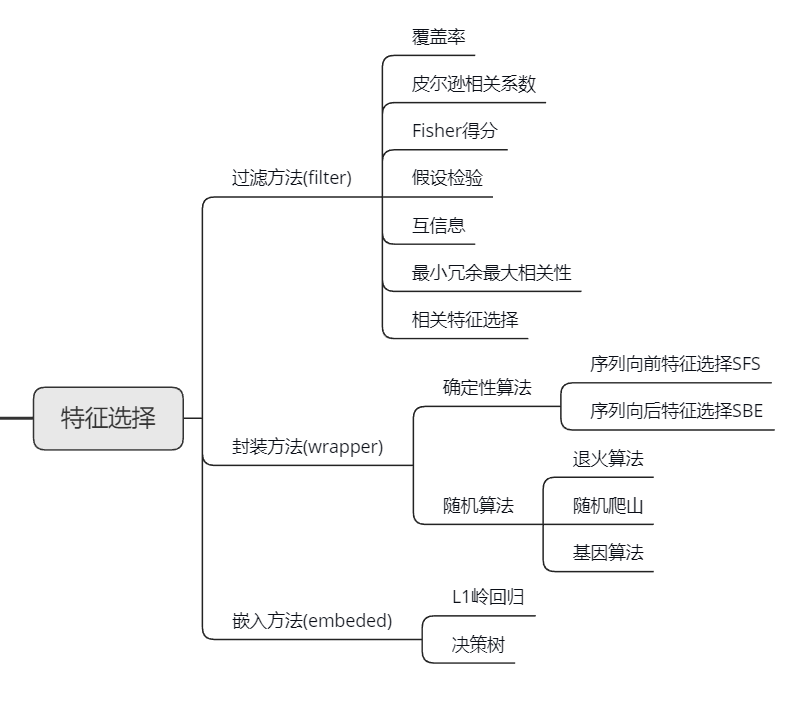
特征工程之特征选择 发表于 2020-08-05 更新于 2020-11-08 分类于 数据挖掘 特征选择,即对于生成的特征集合进行筛选,得到一个子集,主要有一下三个目的 简化模型,增加可解释性 改善性能,并且节省存储空间和计算开销 改善通用性,降低过拟合风险。 特征选择主要分为三种方法,过滤方法、封账方法和嵌入方法过滤方法Filter过滤方法主要特点: 不依赖与机器学习算法 一般分为单变量和多变量 单变量一般基于特征变量与目标变量之间的相关性或互信息,根据相关性排序,过滤掉最不相关特征 多变量有基于相关性和一致性的特征选择 阅读全文 »
特征工程之特征构建 发表于 2020-07-11 更新于 2020-08-29 分类于 机器学习 类别特征 几乎总是需要做一些处理 类别特征种类过多会造成稀疏数据 难以填充缺失值 热独编码(Onehot-encoding) 通常和大多数线性算法一起使用 稀疏格式对内存友好 大多数方法无法处理缺失或者不可见数据 对于没有大小区分的类别特征,可以使用Oneshot-encoding 哈希编码(Hash encoding) 阅读全文 »
word embedding作用及用法 发表于 2020-06-07 更新于 2020-06-11 分类于 深度学习 关于word embedding总结词向量表示词语的向量都可以称为词向量,one shot向量和distributed向量都可以表示为词向量热编码表示(one shot)优点 解决了分类器不好解决离散数据的问题, 起到了扩充特征的作用 缺点: 首先,它是一个词袋模型,不考虑词与词之间的顺序(文本中词的顺序信息非常重要) 其次假设词与词之间是独立的(大多数情况下,词与词之间是相互影响的) 最后得到的特征是系数的 阅读全文 »
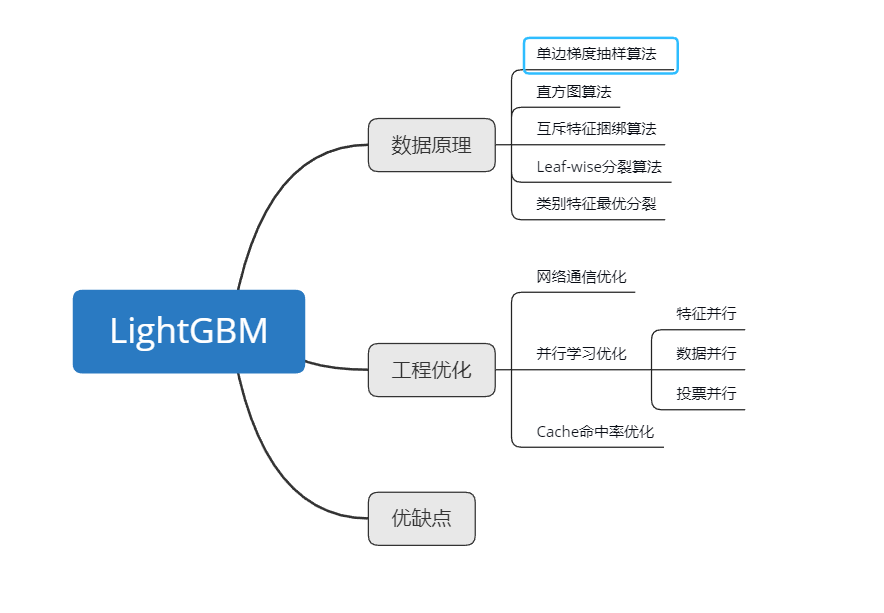
lightGBM论文总结 发表于 2020-03-10 更新于 2020-03-20 分类于 机器学习 LightGBM提出动机为了解决GBDT在海量数据中遇到的问题,让GBDT算法更好的适用于工业实践。1、XGBoost的缺点 需要保存特征值和排序结果,还需要保存排序的索引 每次分裂一个点的时候,都需要计算收益 对cache优化不友好,容易造成cache miss 2、LightGBM的优化 单边梯度采样GOSS 直方图算法 互斥特征捆绑算法 Leaf-Wise分裂算法 类别特征最有分裂 并行学习优化 cache命中率优化 阅读全文 »
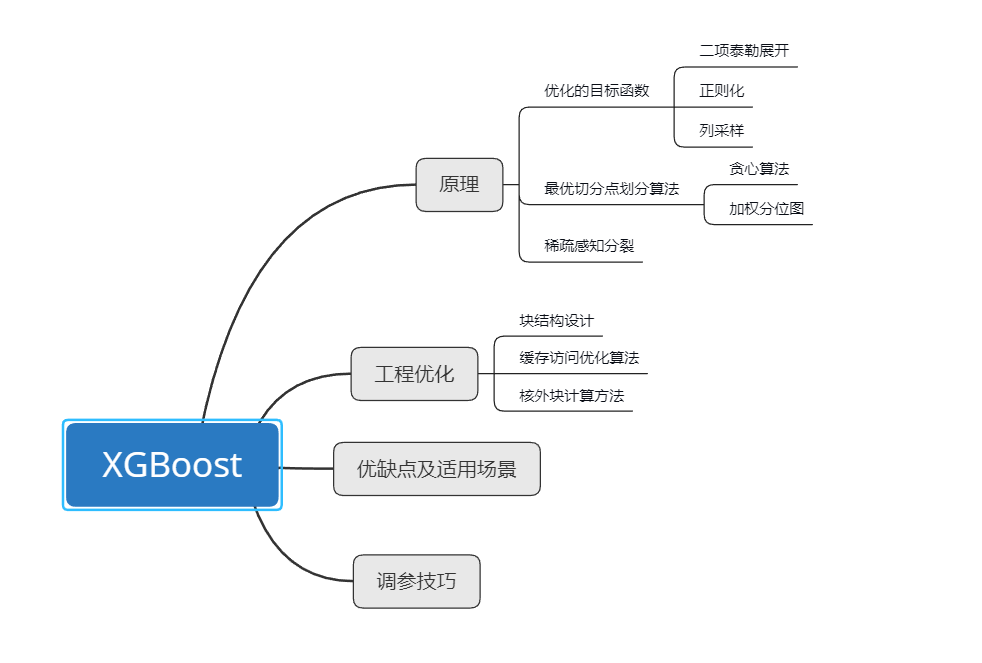
XGBoost原理总结 发表于 2020-03-09 更新于 2020-03-20 分类于 机器学习 Xgboost, 是GBDT的一种实现方式,并且xgboost做了一些改进和优化。1. 原理1.1 优化目标函数对于GBDT方法,都是基模型组成的加法公式。其中$f_k$为基模型,$y_i$表示第$i$个样本预测值。正则化损失函数 阅读全文 »